What Is the Depth vs Width Distinction in Claude Code Agents? /goal vs Workflows
The /goal command loops one agent until criteria are met. Dynamic workflows fan out hundreds of agents in parallel. Learn which pattern fits your task.

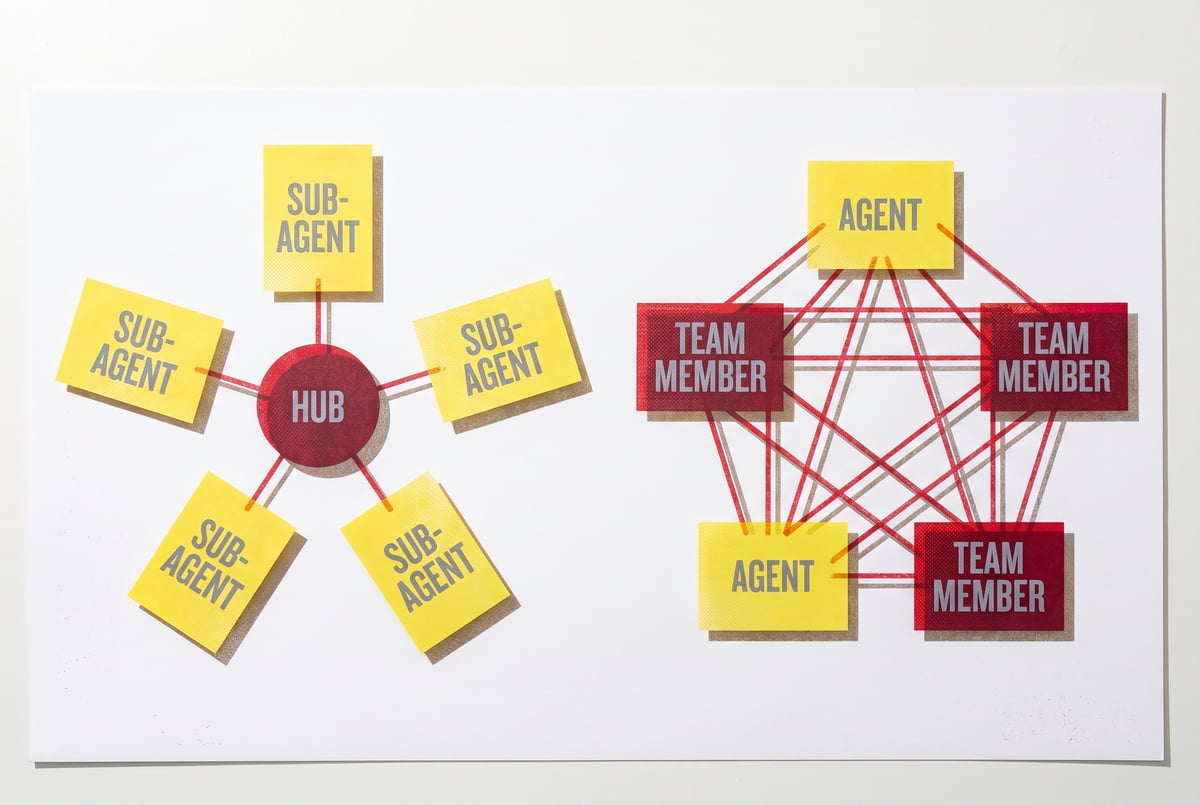
Two Ways to Scale an Agent: Going Deep vs. Going Wide
When you’re working with Claude in an agentic context, one decision shapes everything else: should your agent keep working on a single problem until it’s solved, or should it split the problem across many agents running at once?
This is the depth vs. width distinction in Claude multi-agent systems. It sounds abstract, but in practice it comes down to two very different patterns: the /goal command (depth) and dynamic parallel workflows (width). Understanding which to reach for — and why — is one of the most useful mental models you can build when designing AI workflows.
This article breaks down both patterns, when each fits, and how to choose between them.
What “Depth” Means: The /goal Command
The /goal command in Claude Code is a looping, single-agent pattern. You give it a goal — a success criterion, not just a task — and the agent keeps running, evaluating its progress, and continuing until that criterion is met.
Think of it like a loop with a condition:
while (goal not satisfied):
think → act → evaluateThe agent is not handed a fixed sequence of steps. It decides what to do at each iteration based on what it finds. If it hits a dead end, it backtracks. If it completes a subtask, it reassesses and continues. The loop doesn’t terminate until the goal condition is true.
What Makes /goal Different from a Standard Prompt
Remy is new. The platform isn't.
Remy is the latest expression of years of platform work. Not a hastily wrapped LLM.
With a standard prompt, Claude does one pass. It reads your input, generates a response, and stops. There’s no built-in mechanism for it to check whether it actually solved the problem and try again if it didn’t.
/goal changes this. It introduces persistence. The agent keeps a mental model of what “done” looks like and uses that as the exit condition. This is especially powerful for tasks that are:
- Hard to scope upfront (you know the destination, not the path)
- Iterative by nature (debugging, research, refactoring)
- Prone to partial failure (first attempt might uncover new unknowns)
A Concrete Example: Debugging with /goal
Say you give an agent the goal: “Fix all failing tests in this codebase.”
A standard prompt might run the tests, see five failures, and patch three of them — then stop. Mission half-complete.
With /goal, the agent runs the tests, patches the failures it can identify, runs the tests again, sees two remaining failures, investigates further, patches those, and continues until the test suite is green. The goal condition — “all tests passing” — is the actual stopping criterion.
This is the depth pattern: one agent, one thread, persistent iteration.
What “Width” Means: Dynamic Parallel Workflows
The width pattern is the opposite. Instead of one agent running deeper and deeper into a problem, you fan out: many agents running simultaneously, each working on a slice of the problem.
Dynamic workflows take a task and decompose it into parallel subtasks that agents can execute concurrently. Rather than doing work sequentially, the system distributes it across an array of agents and collects results when they’re done.
The mental model here is a map-reduce:
1. Decompose task into N subtasks
2. Spawn N agents in parallel
3. Each agent completes its subtask
4. Aggregate resultsWhat Makes Dynamic Workflows Different
The key difference is parallelism. If your problem has parts that don’t depend on each other, there’s no reason to do them one at a time. Dynamic workflows let you do them all at once.
This is especially valuable when:
- The problem has natural partitions (e.g., analyze 500 documents)
- Speed matters and tasks are independent
- You need diverse perspectives or outputs (e.g., generate 20 variations of something)
- The bottleneck is throughput, not reasoning depth
A Concrete Example: Content Audit with Parallel Agents
Say you need to audit 300 product pages for SEO quality. Each page needs to be evaluated independently — there’s no reason the evaluation of page 1 needs to happen before page 2.
A depth-first approach would have one agent work through all 300 pages, one by one. Depending on the model latency and task complexity, this could take hours.
A dynamic workflow would spin up 300 agents (or batches of agents), each evaluating one page. All evaluations happen in parallel, and results get collected into a final report. The same work might complete in minutes.
The width pattern trades sequential depth for parallel speed.
Depth vs. Width: How to Choose
This is where most people get stuck. Both patterns work for many tasks, so what’s the deciding factor?
Here’s a simple framework:
| Dimension | Use Depth (/goal) | Use Width (Dynamic Workflows) |
|---|---|---|
| Task structure | Sequential, dependent steps | Independent, parallelizable parts |
| Primary constraint | Quality / correctness | Throughput / speed |
| Problem shape | One problem, many iterations | Many problems, one pass each |
| Stopping condition | Goal-based (when done, stop) | Count-based (when all N done, stop) |
| Cost sensitivity | Lower — one agent at a time | Higher — many agents simultaneously |
Plans first. Then code.
Remy writes the spec, manages the build, and ships the app.
When Depth Wins
Depth is the right call when solving the problem requires context that builds over time. If each step informs the next — if the agent needs to know what it found in step 3 before it can decide what to do in step 4 — parallel agents can’t help you. They each start from scratch.
Debugging is the clearest case. The agent discovers something on the first run, updates its hypothesis, acts on it, discovers something new, and so on. This is a chain where each link depends on the previous one. Parallelism doesn’t apply.
Research is another good case. If you’re asking an agent to develop a nuanced understanding of a topic — reading sources, synthesizing, going deeper where needed — the depth pattern maintains a coherent thread of understanding across the whole process.
When Width Wins
Width wins when the problem is embarrassingly parallel. The term “embarrassingly parallel” comes from computer science and refers to problems where subtasks have no dependencies on each other — they can literally be run in any order, or simultaneously, without affecting correctness.
Large-scale data processing, content generation at scale, running test suites across independent modules, summarizing a large corpus of documents — these are width problems. There’s no benefit to running them sequentially, and significant cost in doing so.
Width also wins when you want diversity of output. If you’re generating marketing copy, running 20 agents in parallel (with slightly different prompts or temperatures) gives you 20 genuinely different options to evaluate. One agent running 20 times sequentially gives you 20 outputs too, but with lower variation and no speed benefit.
How These Patterns Interact: Hybrid Approaches
In practice, the most capable multi-agent systems use both patterns — and they’re not mutually exclusive.
A common hybrid looks like this:
- Width first: Fan out agents to gather information or complete parallel subtasks.
- Depth next: One agent (or a small set) synthesizes the results, iterating until the synthesis meets quality criteria.
Example: research + report generation. You spawn 10 agents to pull and summarize sources on a topic (width). Then a single summarization agent takes those 10 summaries and iteratively drafts and refines a final report until it meets the quality bar (depth).
Another hybrid: nested parallelism. A top-level orchestrator uses width to split work across a set of sub-orchestrators. Each sub-orchestrator uses depth (/goal) to complete its assigned chunk. Results flow back up to the top level.
Anthropic’s documentation on building effective agents covers several of these compositional patterns in detail.
The Role of an Orchestrator Agent
Both /goal and dynamic workflows often involve an orchestrator — an agent whose job is to plan and coordinate, not execute directly. The orchestrator decides which pattern to use (and when to switch), dispatches work, handles failures, and aggregates results.
Everyone else built a construction worker.
We built the contractor.
One file at a time.
UI, API, database, deploy.
In Claude Code, the orchestrator can invoke subagents via the Task tool. Each subagent may itself use /goal to iterate until its task is complete before returning results to the orchestrator. This is the standard pattern for complex, multi-step agentic pipelines.
Common Mistakes When Choosing Between Depth and Width
Using width when depth is needed
The most common mistake is parallelizing a task that has sequential dependencies. If subtask B depends on the output of subtask A, you can’t run them simultaneously. Trying to do so means one agent will lack context the other discovered, leading to inconsistent or incorrect results.
Watch for: any task where “it depends on what we find” is a common phrase during planning. That’s a signal for depth.
Using depth when width is faster
The opposite: running sequentially through independent tasks when there’s no reason not to parallelize. This is mainly a cost-in-time problem. The work gets done correctly, just slowly.
Watch for: any task where you can describe it as “do X for each of these N things, where X is the same for all of them.” That’s a signal for width.
Forgetting to define the goal condition
When using /goal, the stopping condition needs to be concrete and evaluable. “Do good research” isn’t a goal — the agent has no way to evaluate whether it’s done. “Produce a 500-word summary with citations from at least 3 primary sources” is evaluable.
Vague goal conditions cause agents to either stop too early (they judge themselves done before they are) or loop endlessly (they can’t confidently determine they’re finished).
Underestimating cost at width
Running 500 agents in parallel costs roughly 500x what running one agent costs, at least in terms of model API usage. This is often the right tradeoff — but it needs to be a conscious one. Before fanning out at scale, estimate the cost and make sure the speed or throughput benefit justifies it.
Where MindStudio Fits
If you’re thinking about these patterns beyond Claude Code — building multi-agent workflows that run autonomously, connect to business tools, or need to be triggered and managed outside a terminal session — this is where MindStudio comes in.
MindStudio lets you build both depth-based and width-based multi-agent workflows visually, without writing infrastructure code. You can define an agent that loops against a goal condition, or you can fan out parallel subagents across a dataset and collect their results — all from a no-code builder.
The practical upside: you’re not managing prompt construction, retry logic, rate limiting, or result aggregation manually. That infrastructure is handled, so you can focus on designing the workflow logic itself.
For developers building agents with Claude Code or other frameworks, MindStudio also offers an Agent Skills Plugin — an npm SDK that lets your agents call 120+ typed capabilities as simple method calls. Things like agent.sendEmail(), agent.searchGoogle(), or agent.runWorkflow() let Claude Code agents delegate specific actions to MindStudio rather than reinventing that plumbing from scratch.
If you’re building anything that benefits from these multi-agent patterns at scale, MindStudio is worth exploring. You can start free at mindstudio.ai.
FAQ
What is the /goal command in Claude Code?
Built like a system. Not vibe-coded.
Remy manages the project — every layer architected, not stitched together at the last second.
/goal is a Claude Code feature that puts an agent into a persistent loop. Instead of completing one pass and stopping, the agent keeps running — thinking, acting, and evaluating — until it determines that a stated goal condition has been met. It’s designed for tasks where you know the destination but not the exact path, like fixing all failing tests or completing a research objective.
What is a dynamic workflow in the context of multi-agent systems?
A dynamic workflow is a pattern where a task is decomposed into subtasks and multiple agents are spun up to handle those subtasks simultaneously. Rather than working through a problem sequentially, the system fans out work across parallel agents and collects results when they’re done. This is the “width” pattern — optimized for throughput and speed rather than iterative depth.
When should I use /goal vs. parallel agents?
Use /goal (depth) when your task has sequential dependencies — each step builds on what was learned in the previous one. Use parallel agents (width) when your task can be split into independent parts that don’t need to share context. Debugging, research, and iterative refinement are depth problems. Large-scale document processing, content generation at scale, and parallel evaluation are width problems.
Can you mix depth and width in the same workflow?
Yes, and it’s often the right call. A common hybrid: use parallel agents to gather or process information at scale (width), then use a single iterating agent to synthesize the results until they meet a quality bar (depth). Orchestrator-subagent architectures often use exactly this pattern — the orchestrator fans out work, and each subagent iterates until its piece is done.
How do I define a good goal condition for /goal?
The goal condition needs to be concrete and evaluable by the agent itself. “Do thorough research” is too vague. “Produce a summary with citations from at least 5 distinct sources, covering each of the 3 main topics” is evaluable. A good goal condition has a clear pass/fail state the agent can check — not a subjective judgment call.
What are the cost implications of running many agents in parallel?
Running N agents in parallel generally costs N times as much in model API usage as running one agent. For most real-world use cases, the speed benefit justifies the cost — but it’s worth estimating before fanning out at scale. Batching (running groups of agents rather than all at once) is a common way to balance speed and cost. Some platforms also offer preferential pricing for high-volume automated agent runs.
Key Takeaways
- Depth (
/goal) means one agent looping until a goal is met — best for sequential, iterative, dependency-rich tasks. - Width (dynamic workflows) means many agents running in parallel — best for independent, high-throughput tasks where speed matters.
- The deciding factor is task structure: if steps depend on each other, go deep. If they don’t, go wide.
- Hybrid approaches are common — fan out for data collection, then iterate for synthesis.
- Goal conditions for
/goalneed to be concrete and self-evaluable, not vague. - Infrastructure concerns (cost, rate limits, aggregation) are real — plan for them.
MindStudio makes it practical to implement both patterns without building the infrastructure from scratch. If you’re ready to put these patterns to work, start with MindStudio for free and see how quickly a multi-agent workflow can come together.