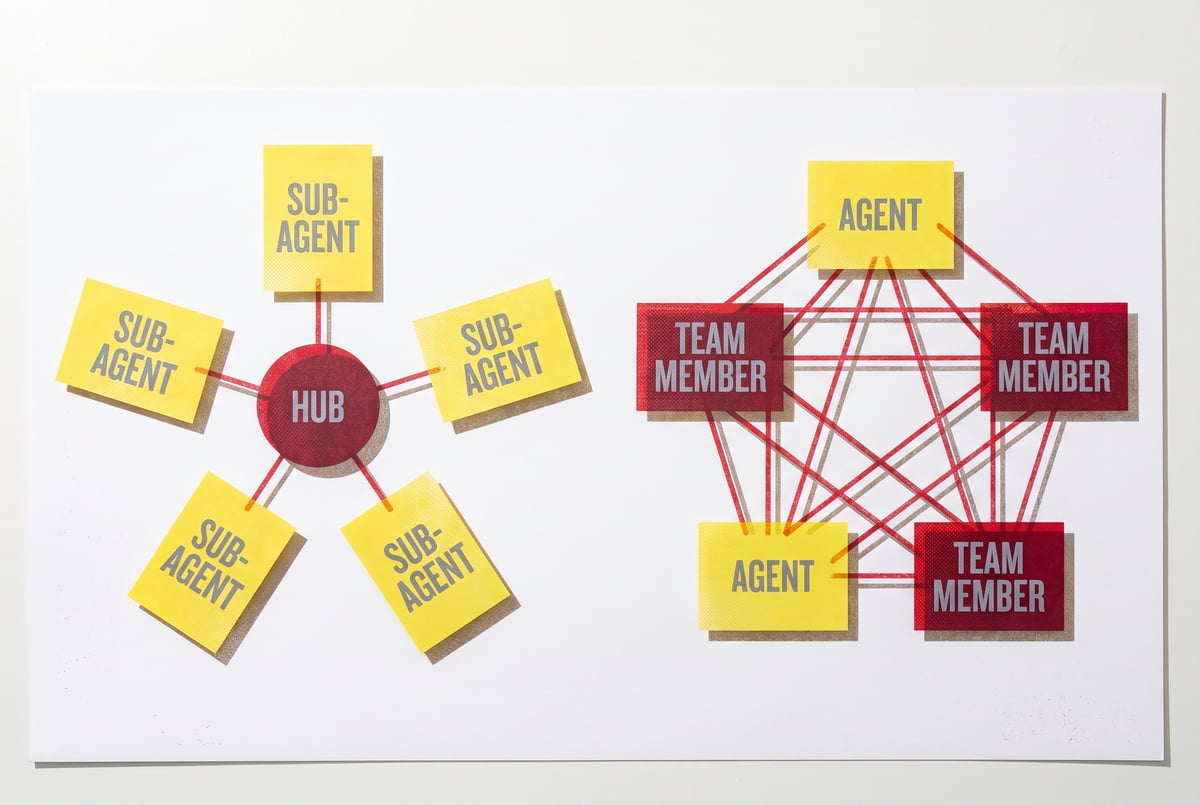
What Is Claude Code Ultra Plan's Multi-Agent Architecture? Three Explorers Plus One Critic
Ultra Plan spins up three parallel exploration agents and one critique agent in Anthropic's cloud. Here's why that produces better plans faster.

How Three Explorer Agents and One Critic Make Claude Code’s Ultra Plan Different
When you ask an AI to plan a complex refactor or design a new system from scratch, a single agent has a real structural problem: it commits to an approach early and then defends it. It doesn’t naturally explore competing ideas in parallel. It anchors.
Claude Code’s Ultra plan takes a different approach. Instead of one agent working sequentially, it spins up a multi-agent architecture where three parallel exploration agents each independently attempt the problem, and a dedicated critic agent evaluates their outputs before producing a final answer. The result is that you get something closer to how a good engineering team actually works — multiple perspectives, then ruthless evaluation.
This article explains exactly how that architecture works, why the three-plus-one pattern matters, and what it tells you about the direction multi-agent AI systems are heading.
Why Single-Agent Architectures Hit a Ceiling
Before covering the Ultra plan’s multi-agent setup, it’s worth understanding the problem it solves.
A single large language model, even a very capable one, generates tokens sequentially. Each token conditions the next. This means the model’s first paragraph shapes everything that follows. Early framing choices — which approach to take, which tradeoffs to prioritize — propagate through the entire response and are hard to reverse.
For simple tasks, this is fine. But for complex planning, architecture decisions, or debugging non-obvious problems, that sequential commitment creates blind spots.
The Anchoring Problem in AI Reasoning
Remy doesn't build the plumbing. It inherits it.
Other agents wire up auth, databases, models, and integrations from scratch every time you ask them to build something.
Remy ships with all of it from MindStudio — so every cycle goes into the app you actually want.
Research on LLM reasoning has shown that models tend to anchor on the first plausible solution they generate. Once an approach is “in context,” the model is statistically more likely to continue developing it than to abandon it for something better.
This isn’t a bug — it’s a natural consequence of how autoregressive generation works. But it means a single agent has a hard time genuinely considering two fundamentally different solutions and choosing between them with fresh eyes.
What Changes When You Add More Agents
Multi-agent architectures address anchoring by running separate agents with separate context windows. Each agent starts fresh. Each can arrive at a different approach. There’s no shared context that biases them toward a common answer.
Then — and this is the critical part — a separate evaluation step can compare those approaches on their merits. The evaluator isn’t defending the work it did. It’s assessing work done by others.
This is the core insight behind Claude Code Ultra’s architecture: separate generation from evaluation.
The Three Explorer Agents: What They Actually Do
In Claude Code Ultra, when you submit a complex task — building a feature, designing a database schema, debugging a nasty concurrency issue — the system doesn’t immediately generate a solution. It first deploys three parallel sub-agents, each tasked with independently exploring the problem.
These are sometimes called “explorer agents” because their job is to explore the solution space without coordinating with each other.
Independent Context Windows
Each explorer agent receives the same initial task but runs in its own context window. Because they don’t share state or intermediate reasoning, they can arrive at genuinely different conclusions. One might prioritize performance. Another might take a more defensive, readable approach. A third might propose a more radical architectural change.
This independence is what makes the parallelism valuable. If the agents were sharing context, they’d converge. Separate context windows preserve diversity.
Parallel Execution in Anthropic’s Infrastructure
Running three agents simultaneously means the work happens in Anthropic’s cloud, not on your local machine. The explorers are spawned as actual separate model invocations running concurrently. This is why Ultra tier requires more compute — it’s not that each individual call is more complex, it’s that you’re running multiple calls at once.
For users, this translates to better outputs without proportionally longer wait times. Three agents running in parallel takes roughly the same wall-clock time as one agent running sequentially, but you get three independent perspectives.
Diversity in Approach, Not Just Wording
The goal isn’t three ways of saying the same thing. Good multi-agent explorer setups are designed to produce substantively different approaches. In practice this can mean:
- Different architectural patterns (microservices vs. monolith, for example)
- Different tradeoff profiles (optimize for latency vs. correctness)
- Different levels of abstraction (implement from scratch vs. use a library)
- Different risk tolerances (safe and verbose vs. elegant and minimal)
The diversity in outputs is what gives the critic agent something meaningful to work with.
The Critic Agent: Why Evaluation Is a Separate Job
Once the three explorers have generated their approaches, a fourth agent — the critic — takes all three outputs and evaluates them against the original requirements.
One coffee. One working app.
You bring the idea. Remy manages the project.
This is a fundamentally different kind of reasoning task than exploration. Exploration is generative: produce something plausible and develop it. Critique is evaluative: assess multiple options against criteria and identify weaknesses.
Why You Want Critique to Be Separate
There’s a reason code review is done by someone other than the person who wrote the code. The author is too close to their own reasoning to spot its gaps.
The same logic applies to AI agents. An agent that generates a plan and then self-critiques it is working against its own anchoring bias. It built a mental model while generating, and now it’s reviewing from inside that model.
A separate critic agent doesn’t have that baggage. It receives the three outputs cold, with no attachment to any of them.
What the Critic Is Actually Evaluating
The critic isn’t just picking the “best” answer. It’s doing several things:
- Checking completeness: Did each explorer actually address all requirements, or did some take shortcuts?
- Identifying failure modes: What could go wrong with each approach that the explorer didn’t flag?
- Comparing tradeoffs: Given what the user actually asked for, which approach’s tradeoffs are most appropriate?
- Synthesizing if needed: Sometimes the best answer isn’t any single explorer’s output but a combination — take the architecture from Explorer 1, the error handling from Explorer 2, and the test strategy from Explorer 3.
This last point is important. The critic doesn’t just select; it can synthesize. The final output might not exist verbatim in any of the three exploration runs.
How the Coordination Works End-to-End
Let’s trace a complete example. Say you ask Claude Code Ultra to design a rate-limiting system for an API.
- Task intake: Claude Code parses your request and determines this is complex enough to warrant multi-agent exploration.
- Explorer dispatch: Three sub-agents are spawned in parallel, each receiving the full task description with no knowledge of what the others will produce.
- Exploration phase: Each agent generates its own approach — perhaps token bucket, sliding window, and a Redis-backed distributed solution.
- Critic ingestion: The critic agent receives all three outputs plus the original task specification.
- Evaluation phase: The critic identifies that your task mentioned “distributed” requirements you care about, which makes Explorer 3’s approach most relevant, but notes Explorer 1’s failure handling is better and should be incorporated.
- Final synthesis: The critic produces an output that combines the best elements or clearly recommends one approach with specific modifications.
You receive something that has been stress-tested across multiple independent reasoning paths — not just one agent’s best first attempt.
Why This Pattern Produces Better Plans Faster
The “faster” part is worth emphasizing. Parallelism isn’t just about quality — it’s about efficiency.
The Time Math
If each exploration agent takes X seconds to generate an approach, three sequential explorations take 3X seconds. Three parallel explorations still take roughly X seconds (with a small overhead for coordination). Add the critic pass — say 0.5X seconds — and you get roughly 1.5X total time to produce a higher-quality output than any single agent would generate.
You get diversity of approaches at roughly the cost of depth of a single approach.

Confidence Calibration
When all three explorers converge on a similar solution, that’s a strong signal the approach is sound. When they diverge significantly, the critic’s job becomes more important — and the final output will likely include more explicit tradeoff discussion, which is exactly what you need for a genuinely hard decision.
This calibration is valuable. Single-agent outputs don’t tell you whether the AI was confident or just committed. Multi-agent architectures surface disagreement.
Reduced Need for Iteration
One of the practical benefits users report is fewer follow-up prompts needed to get to a good answer. The multi-agent process front-loads the exploration that users would otherwise have to manually request (“actually, can you show me an alternative approach?”). You get that diversity without asking for it.
How This Relates to Broader Multi-Agent Design Patterns
The three explorers plus one critic pattern isn’t a Claude-specific invention. It’s an application of established ideas in multi-agent system design.
Mixture of Agents
Mixture of Agents (MoA) is a research pattern where multiple LLMs contribute to a final output, and an aggregator model synthesizes their responses. Studies from publications like Together AI’s MoA research have shown this approach outperforms single models on reasoning benchmarks. Claude Code Ultra’s architecture applies this principle within a single Claude model family, using independent sampling to create diversity rather than different model weights.
Critic-Based Refinement
Critique and revision loops have been studied extensively in AI alignment research. Constitutional AI, for example, uses a model to critique and revise its own outputs according to a set of principles. Claude Code’s approach separates the critic into its own agent entirely, which avoids self-consistency bias more effectively than critique-and-revise within a single context window.
Orchestrator-Subagent Patterns
Anthropic’s own documentation on Claude’s agentic capabilities describes orchestrator-subagent architectures where a central orchestrating model directs specialized sub-agents. The Ultra plan architecture is a specific instantiation of this: the orchestrator manages the explorer dispatch and the critic serves as a specialized evaluation subagent.
Building Similar Multi-Agent Workflows in MindStudio
If you’re a developer who wants to build your own multi-agent pipelines — not just use Claude Code’s, but create custom ones for your own products or internal tools — MindStudio is worth knowing about.
MindStudio is a no-code platform for building AI agents and automated workflows. It supports any of 200+ models, including Claude, and you can wire together multi-agent architectures visually — no infrastructure work required.
For the specific pattern discussed in this article, you could build something like this in MindStudio:
- Parallel branches: Send the same task to three separate AI agents running concurrently, each configured with different system prompts that bias them toward different solution strategies.
- Aggregation step: Feed all three outputs into a fourth agent configured to act as an evaluator/critic with explicit scoring criteria.
- Conditional output: Route the final synthesis to wherever you need it — Slack, Notion, a webhook, an email — using MindStudio’s 1,000+ built-in integrations.

The average workflow like this takes around 30–60 minutes to build, and you don’t need to manage any infrastructure. The multi-agent coordination, rate limiting, and retries are handled for you.
You can try MindStudio free at mindstudio.ai.
If you’re interested in building agentic workflows more broadly, MindStudio’s guide to building AI agents covers the patterns in more detail — including how to design effective critic prompts and manage parallel execution.
FAQ
What is Claude Code Ultra plan?
Claude Code is Anthropic’s AI coding assistant that runs in your terminal. The Ultra plan is the highest subscription tier, offering the most capable version of the system including multi-agent architecture features, higher usage limits, and access to the most capable Claude models. It’s designed for users with demanding, complex coding and planning tasks.
How many agents does Claude Code Ultra use?
Claude Code Ultra uses four agents for complex tasks: three parallel “explorer” agents that independently generate approaches, and one critic agent that evaluates the explorers’ outputs and synthesizes a final response. This is in contrast to standard single-agent setups where one model handles the entire task sequentially.
Does multi-agent mean Claude Code is running multiple separate AI models?
Not necessarily. The multiple agents in Claude Code Ultra are typically separate invocations of Claude models running in parallel — independent instances with separate context windows — rather than entirely different AI models. The power comes from independent context windows and parallel execution, not from model diversity.
Why does the critic agent produce better results than self-critique?
Self-critique suffers from anchoring bias: the agent that generated an answer has already committed to a line of reasoning, making it less likely to spot the fundamental weaknesses of its own approach. A separate critic agent starts fresh, with no investment in any of the three approaches, and can evaluate them more objectively. This mirrors why peer code review typically catches more bugs than author self-review.
Is the Ultra plan’s multi-agent architecture always active?
The multi-agent architecture is typically invoked for complex tasks where exploration and planning are valuable — architectural decisions, multi-step implementations, debugging complex issues. For simple or straightforward requests, Claude Code may not spin up the full multi-agent pipeline, since the overhead wouldn’t add meaningful value over a direct response.
How does this compare to other AI coding tools?
Most AI coding assistants use a single-agent approach — one model generates, and you iterate through follow-up prompts. The parallel exploration plus critic pattern is a meaningful architectural difference that shifts the diversity and evaluation work from the user to the system. Tools like GitHub Copilot, Cursor, and standard Claude operate primarily in single-agent mode; the multi-agent approach in Claude Code Ultra is currently more sophisticated in how it handles complex planning tasks.
Key Takeaways
- Single agents anchor early: Sequential generation causes commitment to the first plausible approach, which becomes hard to reverse.
- Three explorers create genuine diversity: Independent context windows mean each agent can arrive at fundamentally different solutions, not just differently worded versions of the same idea.
- The critic works without bias: A separate evaluation agent has no attachment to any explorer’s work, making its assessment more reliable than self-critique.
- Parallel execution preserves speed: Running three explorers simultaneously means you get diverse approaches in roughly the time it would take to generate one.
- Synthesis often beats selection: The critic doesn’t just pick a winner — it can combine the best elements from multiple explorers into a response that none of them produced alone.

The three-plus-one pattern reflects where serious AI tooling is heading: away from single-model calls and toward coordinated systems where generation and evaluation are treated as distinct jobs. If you want to build similar architectures for your own use cases, platforms like MindStudio make it practical without requiring you to manage the underlying infrastructure yourself.