Claude Code Source Leak: The Three-Layer Memory Architecture and What It Means for Builders
The Claude Code source leak revealed a self-healing memory system using memory.md as a pointer index. Here's what it means for building your own AI agents.

What the Claude Code Leak Actually Revealed
When the Claude Code system prompt and internal scaffolding leaked in mid-2025, most of the coverage focused on the novelty of it — a peek behind the curtain of how Anthropic’s flagship coding agent actually works. But beneath the surface-level curiosity, there was something genuinely useful for anyone building AI agents: a clear, implementable memory architecture that holds up under real-world use.
The leak showed that Claude Code doesn’t just rely on its context window to remember things. It uses a structured, three-layer memory system built around a file called memory.md that acts as a pointer index. The agent writes to it, reads from it, and uses it to navigate a larger web of structured memory files. It’s a practical pattern — not theoretical — and it’s one that builders working with multi-agent systems or autonomous workflows should pay close attention to.
This article breaks down the architecture layer by layer, explains what “self-healing memory” actually means in practice, and covers what all of this means if you’re trying to build your own capable AI agent.
The Core Problem: AI Agents Forget Things
Before getting into the architecture, it’s worth understanding the problem it’s solving.
One coffee. One working app.
You bring the idea. Remy manages the project.
Large language models have a context window — a fixed amount of text they can “see” at any given moment. Claude 3.5 Sonnet, for example, supports 200K tokens. That sounds like a lot until you’re running a long coding session with a large codebase, multiple files, ongoing conversations, and tool outputs. Context fills up fast.
The naive solution is to just stuff everything into the prompt. But that’s expensive, slow, and still eventually hits limits. The smarter solution — which the Claude Code leak made visible — is to treat memory as an external system, not as part of the context window itself.
This is exactly what the three-layer architecture addresses.
The Three-Layer Memory Architecture
Layer 1: In-Context Memory
This is the most obvious layer. It’s whatever is currently loaded into the active context window — the conversation history, recent tool outputs, the current file being edited, and any instructions that have been injected into the system prompt.
In-context memory is fast and immediately usable, but it’s ephemeral. The moment a session ends, it’s gone. And even within a session, as the context fills up, older information gets pushed out or compressed.
Claude Code treats this layer as a working scratchpad. It’s where active reasoning happens, but it’s not where persistent knowledge lives.
Layer 2: External File Memory (The memory.md Layer)
This is the key insight from the leak. Claude Code writes structured information to files on disk — and memory.md serves as the index that organizes all of it.
Rather than dumping everything into one giant memory file, the architecture uses memory.md as a pointer system. It contains references to other memory files, each focused on a specific domain or type of information. Something like:
memory/project-context.md— what the project is, its goals, its constraintsmemory/decisions.md— architectural choices that have been made and whymemory/code-patterns.md— conventions and patterns being followed in this codebasememory/user-preferences.md— how this particular user likes to work
When Claude Code needs to recall something, it reads memory.md first to find the right pointer, then loads the specific file it needs. This keeps the loaded context minimal and relevant, rather than pulling everything into the window at once.
The “self-healing” aspect comes from the agent’s ability to update these files itself. If a decision changes, if new context is established, or if a previous entry becomes outdated, Claude Code can rewrite the relevant file and update the pointer index. No human has to manually maintain the memory system — the agent does it.
Layer 3: Structural Project Memory (CLAUDE.md)
The third layer operates at the project level, not the session level. CLAUDE.md files are placed in project directories and serve as a kind of persistent constitution for how Claude should behave within that context.
This is different from memory.md. Where memory.md is dynamic — updated frequently as new information emerges — CLAUDE.md tends to be more stable. It holds things like:
- The project’s overall architecture and goals
- Coding standards and style preferences
- Which files or directories are off-limits
- Instructions for how to run tests or builds
- Context that should always be available, every session
Other agents ship a demo. Remy ships an app.
Real backend. Real database. Real auth. Real plumbing. Remy has it all.
When Claude Code starts a new session in a project directory, it reads the CLAUDE.md file first. This gives it immediate situational awareness without needing to re-establish context from scratch every time.
Together, the three layers create a system where:
- Immediate context is handled in-window
- Session and evolving knowledge is stored in
memory.mdand its referenced files - Stable project-level knowledge lives in
CLAUDE.md
What “Self-Healing Memory” Actually Means
The phrase sounds more sophisticated than it is in practice, which is a good thing.
Self-healing memory means the agent is responsible for maintaining the accuracy of its own memory files. If Claude Code learns that a previous assumption was wrong, it doesn’t just note the correction in the conversation — it rewrites the relevant memory file so that correction persists.
This is the behavior that makes long-running agents actually useful. Without it, you end up with agents that repeat mistakes, forget context between sessions, or require constant human correction. With it, the agent gradually builds up an accurate, project-specific knowledge base that makes it more effective over time.
The mechanism isn’t magic. It’s a combination of:
- Write tools — the agent has explicit tool access to write and modify files
- Read-before-write discipline — before updating a memory file, Claude Code reads the current version to avoid overwriting valid information
- Index maintenance — changes to memory files are reflected in
memory.mdso the pointer structure stays accurate
The key design choice is that memory.md is never used to store actual information — only pointers. This keeps the index small and fast to load, while allowing the actual memory content to grow arbitrarily.
Why This Architecture Works Well
There are a few properties of this design that make it robust in practice.
It’s token-efficient. By using memory.md as a selective index, Claude Code only loads the memory files relevant to the current task. A coding session focused on the authentication module doesn’t need to load the memory entries about database schema conventions.
It’s transparent. The memory system is entirely made of plain text files that a human can read, edit, or audit. There’s no black-box vector database. If something is wrong with the agent’s understanding, you can open a file and fix it.
It survives context resets. When a session ends and a new one begins, the agent isn’t starting from zero. It reads CLAUDE.md and relevant memory/ files and gets back up to speed quickly.
It degrades gracefully. If a memory file gets corrupted or a pointer breaks, the agent can recover by rebuilding from scratch rather than failing in an unrecoverable way.
What This Pattern Gets Wrong (or Leaves Open)
The architecture isn’t perfect. A few real limitations worth noting:
Write conflicts in multi-agent setups. If you run multiple Claude Code instances against the same project, they can race to update the same memory files. The architecture as described in the leak doesn’t include concurrency controls.
Everyone else built a construction worker.
We built the contractor.
One file at a time.
UI, API, database, deploy.
No semantic retrieval. The pointer model works well when you know roughly which memory domain is relevant. But if the agent needs to find information across many memory files based on meaning rather than structure, a flat file system with pointers doesn’t help much. A vector database or embedding-based retrieval layer would be more powerful here.
Memory drift over long projects. Over time, memory files can accumulate outdated or contradictory information. The self-healing mechanism helps, but it depends on the agent noticing the contradiction. Subtle drift can persist undetected.
Storage isn’t free. For systems where every file read and write is an API call (e.g., reading from a remote repository), the overhead of maintaining a pointer index adds latency.
These aren’t dealbreakers, but they’re important to account for if you’re adapting this pattern for your own systems.
How to Apply This Pattern in Your Own Agents
The three-layer architecture is directly applicable to any autonomous agent you’re building. Here’s how to think about it concretely.
Define Your Memory Domains First
Before writing any code, decide what types of information your agent needs to remember. Group these into logical domains. A customer support agent might have domains like:
- Customer history and preferences
- Product knowledge (stable, rarely changes)
- Open issues and their status (dynamic, changes frequently)
- Agent preferences and escalation rules
Each domain maps to its own memory file. Your index file maps to all of them.
Treat the Index as Write-Protected by Default
Your index file (memory.md in Claude Code’s case) should be updated rarely and carefully. It’s a directory, not a diary. The agent should only modify it when adding a new memory domain or when a pointer becomes invalid — not every time it learns something new.
Give the Agent Explicit Write Tools
The agent needs tool access to read and write files. Don’t rely on the model “imagining” what it would write — give it actual functions:
read_memory(domain)— loads a specific memory filewrite_memory(domain, content)— overwrites a memory fileupdate_index(domain, pointer)— updates the index
These should include validation logic. Before writing, check that the content is well-formed. Before updating the index, check that the pointer refers to a real file.
Use a CLAUDE.md-style Static Layer for Stable Context
For any information that should be available every session — project goals, constraints, conventions — put it in a static configuration file. Load this file at agent startup, always, before anything else. Don’t rely on the agent to remember to load it.
Build a Reconciliation Step
For long-running agents, add a periodic reconciliation step where the agent reviews its memory files for contradictions or outdated entries. This doesn’t need to happen every session — maybe once a week or after major project milestones. But without it, memory drift accumulates.
Where MindStudio Fits Into This
If you want to build agents with persistent memory like this — without wiring together file I/O, tool schemas, and session management from scratch — MindStudio’s visual agent builder handles a lot of that infrastructure automatically.
MindStudio supports multi-step agentic workflows where you can define memory read/write steps as explicit nodes in a flow. You connect an input trigger to a memory lookup step, pass context into the model, then route outputs to a memory update step. The state management between steps is handled by the platform — you’re not building session persistence by hand.
The platform also supports over 1,000 integrations, so “external memory” doesn’t have to mean flat files. You can store agent memory in Notion, Airtable, Google Sheets, or any structured database you’re already using — and your agent reads and writes to those through pre-built connectors.
For teams that want to use Claude itself (or any of the 200+ models MindStudio supports) within a structured memory architecture, MindStudio removes the operational overhead. You define the memory domains, the read/write logic, and the agent’s reasoning steps. The platform handles rate limiting, retries, and state between runs.
You can try MindStudio free at mindstudio.ai — most agents take under an hour to build.
Implications for Multi-Agent Systems
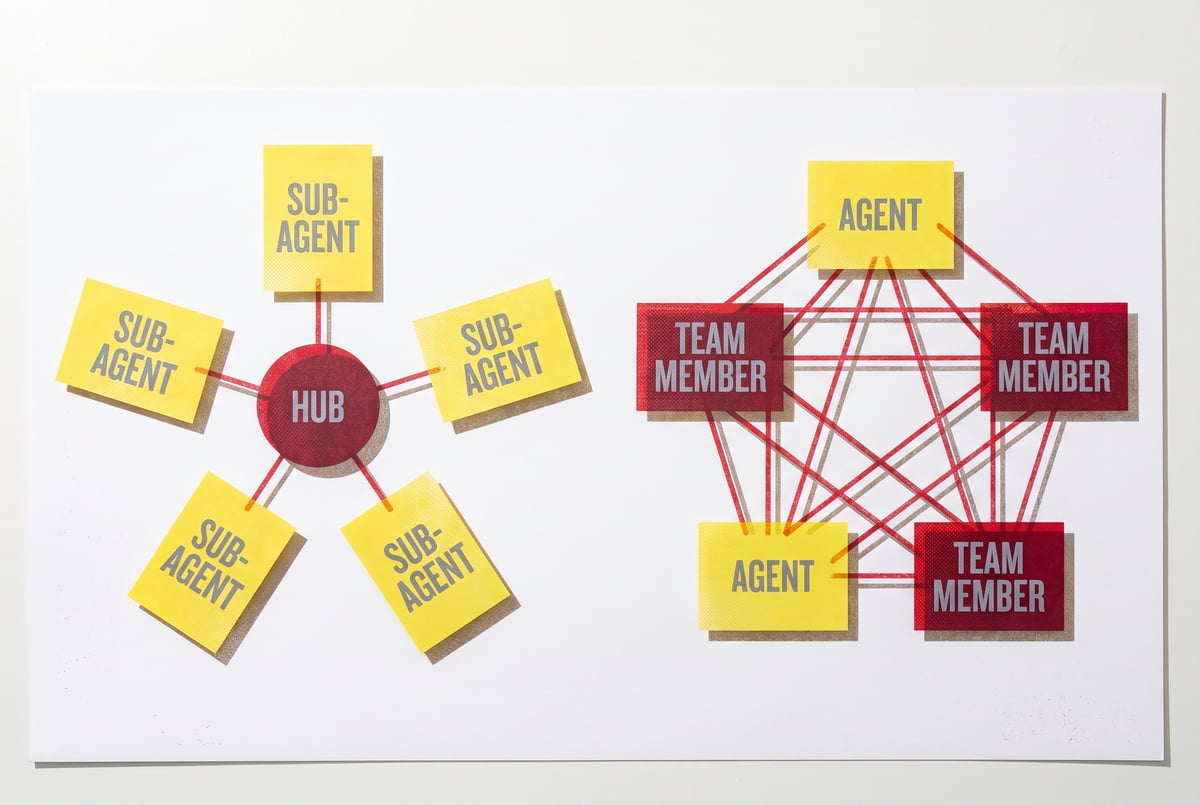
The three-layer memory pattern becomes more interesting — and more complex — when you have multiple agents running simultaneously.
In a single-agent setup, the memory architecture is straightforward: one agent reads and writes to one set of files. In a multi-agent setup, you have agents that may need to share memory, build on each other’s outputs, or specialize in different domains.
A few patterns that work well:
Shared read, isolated write. Multiple agents can read from the same memory.md index and the same CLAUDE.md file. But each agent writes only to its own domain-specific files. A lead agent then periodically reconciles outputs from sub-agents into a unified memory state.
Memory broker pattern. One agent acts as the memory manager. Other agents request memory reads and writes through it, never touching the files directly. The broker handles conflict resolution, validation, and index updates. This is more overhead to set up but cleaner for concurrent workloads.
Event-sourced memory. Instead of overwriting memory files, agents append entries as events. A reconciliation process computes current state from the event log. This prevents write conflicts and gives you a full history, but query performance requires more thought.
The Claude Code architecture doesn’t fully address these patterns — it’s designed for a single agent working in a single project. But the core principle (pointers + domain files + static config) scales into these more complex setups with the right adjustments. For more on how to structure multi-agent coordination, see MindStudio’s guide to building multi-agent workflows.
FAQ
What is the Claude Code memory.md file?
memory.md is an index file used by Claude Code to organize its external memory system. Rather than storing information directly, it contains pointers to other memory files, each focused on a specific domain of knowledge. When the agent needs to recall something, it reads memory.md first to find the right pointer, then loads the specific file. This keeps the active context minimal while allowing the full memory system to grow over time.
How does Claude Code’s self-healing memory work?
Built like a system. Not vibe-coded.
Remy manages the project — every layer architected, not stitched together at the last second.
Self-healing memory means Claude Code can update its own memory files when information changes or becomes outdated. The agent has write access to its memory files and is instructed to rewrite them when it learns that a previous entry is no longer accurate. The memory.md index is updated to reflect any structural changes. No human needs to manually maintain the memory system between sessions.
What is CLAUDE.md and how is it different from memory.md?
CLAUDE.md is a project-level configuration file placed in a project directory. It holds stable, long-term context — coding standards, project goals, architectural decisions, constraints. It’s read at the start of every session and rarely changes. memory.md, by contrast, is dynamic — it’s updated frequently as the agent learns new information within a project. Think of CLAUDE.md as a project brief and memory.md as a running notebook.
Can I build this kind of memory architecture without Claude Code?
Yes. The three-layer pattern — in-context memory, a pointer-indexed file system, and a static config layer — is model-agnostic. You can implement it with any LLM that supports tool use (function calling). You define read/write tools, give the model access to them, and design the memory domain structure for your use case. Platforms like MindStudio make this easier by handling session state and file integrations without requiring you to build that infrastructure yourself. You can also look at how agentic memory systems are being standardized in the broader research community.
Does Claude Code’s memory architecture work for multi-agent systems?
The architecture as described in the leak is designed for single-agent use. Multiple agents writing to the same files simultaneously can cause conflicts. For multi-agent setups, you’d want to add a memory broker pattern (one agent manages all memory writes) or use event-sourced memory where agents append rather than overwrite. The core pointer-index structure still applies — it just needs additional coordination logic around write access. See how MindStudio approaches multi-agent coordination for a practical implementation pattern.
What are the limitations of file-based agent memory?
The main limitations are: no semantic retrieval (you can’t search by meaning, only by structure), potential for memory drift over long projects, write conflicts in concurrent setups, and no versioning by default. For agents that need to search across large knowledge bases based on meaning, a vector database paired with embedding-based retrieval is more appropriate. File-based memory works best when you can clearly define memory domains in advance and the agent’s memory needs are structured rather than open-ended.
Key Takeaways
- The Claude Code leak revealed a three-layer memory system: in-context (active window), external file memory indexed by
memory.md, and project-level static config viaCLAUDE.md. memory.mdis a pointer index, not a storage file — it references domain-specific memory files rather than holding information directly.- Self-healing memory means the agent rewrites its own memory files when information changes, eliminating the need for manual maintenance between sessions.
- The architecture is model-agnostic and directly applicable to any agent you’re building — you need write tools, an index file, and clearly defined memory domains.
- For multi-agent setups, the pattern requires coordination logic (a memory broker or event-sourced writes) to prevent write conflicts.
- Tools like MindStudio let you implement persistent memory architectures visually, without building session management and file I/O infrastructure from scratch.