How to Build a Persistent Memory System for AI Agents: Memarch vs Hermes Compared
Compare Memarch and Hermes memory architectures for AI agents. Learn storage, injection, and recall strategies to stop your agent from forgetting everything.

Why AI Agents Forget Everything (And How to Fix It)
Most AI agents have a fundamental problem: they’re amnesiac by default. Each conversation starts fresh, with no memory of who the user is, what was discussed last week, or what decisions were made. For simple chatbots, that’s fine. For agents doing real work — managing projects, supporting customers, running long-term workflows — it’s a serious limitation.
Building a persistent memory system for AI agents is one of the more complex infrastructure problems in the field right now. Two architectural approaches have emerged as distinct front-runners: Memarch and Hermes. Both solve the same core problem — making AI agents remember — but they take meaningfully different approaches to storage, injection, and recall.
This article breaks down how each architecture works, where each one excels, and how to choose between them when building multi-agent workflows.
Understanding AI Agent Memory: The Four Layers
Before comparing architectures, it helps to understand what “memory” actually means in the context of AI agents. There are four distinct types:
Working Memory
This is what the agent can “see” right now — the active context window. Everything in the current prompt, conversation history, and injected context lives here. It’s fast but finite. Most models top out at 128K–200K tokens, and even with large windows, cramming everything into context gets expensive and noisy.
Episodic Memory
Other agents ship a demo. Remy ships an app.
Real backend. Real database. Real auth. Real plumbing. Remy has it all.
This is the record of specific events and interactions. “On Monday, the user asked about Q3 targets.” “In the last session, the agent completed a competitor analysis.” Episodic memory lets agents build continuity across sessions.
Semantic Memory
This is factual knowledge — things the agent knows about the user, the domain, or the world. “The user’s name is Alex. They work in enterprise sales. Their top priority is reducing churn.” Semantic memory is less about events and more about stable facts.
Procedural Memory
This is knowledge about how to do things — workflows, preferences, and learned behaviors. “When Alex asks for a report, format it as a two-page executive summary.” Procedural memory shapes how an agent acts, not just what it knows.
A robust persistent memory system needs to handle all four types. Memarch and Hermes take different approaches to organizing and retrieving them.
What Is Memarch?
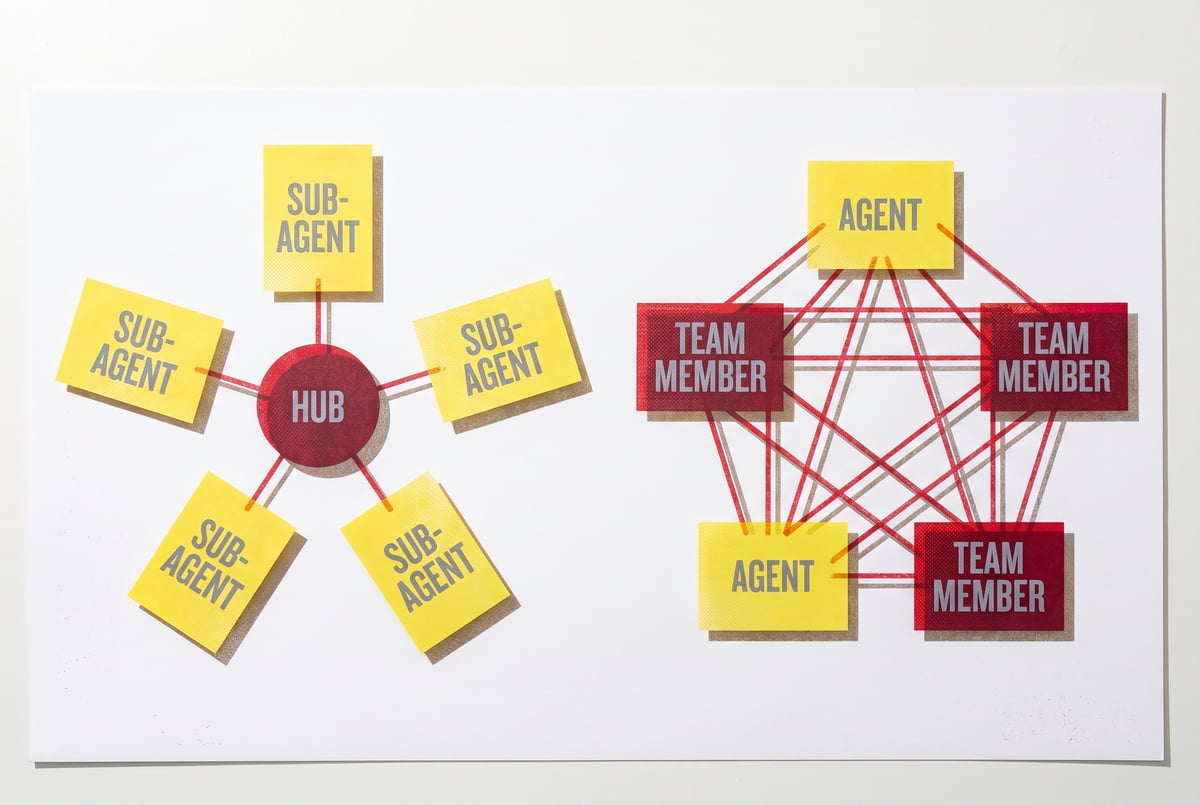
Memarch (short for Memory Architecture) is a structured, schema-driven approach to AI agent memory. The core idea is to treat agent memory like a database: organized into defined types, stored in structured records, and retrieved through explicit queries.
Core Architecture
Memarch organizes memory into explicit tiers. Each tier corresponds to a different memory type and has its own storage backend, retention policy, and retrieval method.
A typical Memarch implementation looks like this:
- Working memory — Managed in-context, with a rolling window and automated summarization
- Episodic store — A timestamped log of interactions, stored in a relational or document database
- Semantic store — A structured knowledge base with a fixed schema (user profile, preferences, domain facts)
- Procedural store — A set of rules or templates that get injected based on context type
The strength of this approach is predictability. Because memory is schema-driven, you always know what you’re storing and where it goes. Retrieval is explicit: fetch the last five user interactions, pull the user profile, inject the relevant workflow template.
Storage Approach
Memarch typically uses a combination of:
- Relational databases (PostgreSQL, MySQL) for structured semantic memory with defined schemas
- Document stores (MongoDB, Firestore) for episodic logs where the structure varies
- Key-value stores (Redis) for fast-access procedural snippets
Memory records in Memarch are discrete objects with defined fields. A user memory record might contain user_id, name, preferences, last_interaction, and active_goals. This makes memory easy to query, update, and audit.
Injection Strategy
Memarch injects memory through a templated system. Before each agent call, a memory retrieval function runs and assembles a structured “memory block” that gets prepended to the system prompt.
This block typically contains:
- A user profile summary (semantic memory)
- Recent interaction highlights (episodic memory)
- Active context — current task, goals, open items
- Relevant procedural rules or templates
The injection is deterministic: the same context inputs always produce the same memory block. This makes Memarch easier to debug and test. If an agent behaves unexpectedly, you can inspect exactly what memory was injected.
Recall Strategy
Recall in Memarch is query-based. The agent, or a memory manager layer, issues structured queries: “get all interactions from the last 7 days,” “retrieve all preferences for user_id 123,” “find all open tasks with status = active.”

This is precise but requires upfront schema design. You need to know in advance what questions you’ll want to ask of your memory, because the schema determines what’s queryable.
What Is Hermes?
Hermes is a retrieval-first memory architecture. Where Memarch emphasizes structure and explicit management, Hermes emphasizes flexibility and semantic search. The core idea is to store memory as a stream of embeddings and retrieve the most relevant pieces using vector similarity.
The architecture’s focus is on passing information dynamically — memory isn’t pre-structured into tiers, it flows to where it’s needed.
Core Architecture
Hermes treats all memory as a single, unified stream of events and facts. Rather than sorting memory into predefined buckets at write time, Hermes stores everything and determines relevance at read time using semantic search.
The three main components are:
- Memory Writer — Processes each interaction and stores it as an embedding alongside the raw text
- Memory Retriever — At query time, takes the current context and finds the most semantically relevant memories
- Memory Injector — Formats retrieved memories and injects them into the prompt
This is closer in spirit to how human memory works: you don’t file memories into labeled folders, you recall them based on relevance to what you’re doing right now.
Storage Approach
Hermes relies heavily on vector databases:
- Primary store — A vector DB (Pinecone, Weaviate, Chroma, Qdrant) holds all memories as embeddings
- Raw text store — A document store holds the original text for each memory, linked by ID to the embedding
- Recency index — A secondary index tracks timestamps for recency-weighted retrieval
Memory records in Hermes are simpler at the schema level — they’re typically text chunks with metadata (timestamp, agent ID, session ID, memory type tag). The intelligence is in the retrieval, not the structure.
Injection Strategy
Hermes injection is dynamic. Before each agent call, the current user message and recent context get embedded, and a similarity search retrieves the top-N most relevant memories from the vector store.
These retrieved memories are formatted and injected as a context block — similar in form to Memarch, but the contents are determined by semantic relevance, not a fixed template.
This means the agent surfaces different memories depending on what the user is asking about. Ask about project timelines and you get memories about deadlines and milestones. Ask about communication preferences and you get memories about how the user likes to receive updates.
Recall Strategy
Hermes recall uses a combination of:
- Semantic similarity — Vector search for relevance to the current query
- Recency weighting — Recent memories get a ranking boost to prevent the agent from surfacing only old information
- Importance scoring — Some implementations assign importance scores at write time, flagging key decisions, user preferences, or critical facts that should rank higher during retrieval
The tradeoff: recall is more contextually intelligent than Memarch but less predictable. You can’t always know exactly which memories will surface for a given query.
Memarch vs Hermes: A Direct Comparison
Here’s how the two architectures stack up across the dimensions that matter most when building a persistent memory system for AI agents:
| Dimension | Memarch | Hermes |
|---|---|---|
| Storage model | Structured schemas, relational/document DBs | Unstructured embeddings, vector DBs |
| Memory organization | Predefined tiers (working, episodic, semantic, procedural) | Unified stream with metadata tags |
| Injection approach | Deterministic, template-based | Dynamic, similarity-based |
| Recall method | Structured queries (SQL-style) | Semantic vector search + recency weighting |
| Predictability | High — same inputs, same memory block | Lower — depends on embedding similarity |
| Flexibility | Lower — requires schema design upfront | High — works with any memory type |
| Debuggability | Easier — explicit state you can inspect | Harder — emergent retrieval behavior |
| Setup complexity | Higher initial schema design | Lower initial setup, higher tuning complexity |
| Best for | Structured domains with known memory needs | Open-ended agents with diverse memory |
| Scaling | Scales well with relational DB optimizations | Scales well with vector DB sharding |
The Core Tradeoff
The fundamental difference comes down to when structure is applied.
Memarch applies structure at write time — memory is categorized and organized as it’s stored. This makes retrieval fast and predictable but requires knowing your memory taxonomy in advance.
Hermes applies structure at read time — memory is stored loosely and organized when retrieved. This is more flexible and requires less upfront design, but retrieval behavior is harder to audit and control.
Neither is objectively better. The right choice depends on your use case.
When to Use Memarch vs Hermes
Use Memarch When:
Your agent operates in a structured domain. If your agent handles HR queries, customer support tickets, or financial reporting, the memory taxonomy is predictable. You know you need to store user profiles, case histories, and resolution templates. Memarch’s schema-driven approach is a natural fit.
You need auditability. In regulated industries or any context where you need to explain what an agent knew when it made a decision, Memarch’s explicit memory records are much easier to audit than a vector similarity score.
You’re building multi-agent workflows with shared memory. When multiple agents read from and write to the same memory store, a defined schema prevents conflicts and makes coordination cleaner. Agents with clear handoffs and shared task state benefit from Memarch’s structured approach.
Determinism matters. If you’re running automated workflows where the same input should consistently produce the same behavior, Memarch’s predictable injection is valuable. It’s easier to test, debug, and version control.
Use Hermes When:
Your agent handles open-ended, conversational use cases. Personal assistants, research agents, and knowledge workers deal with wildly varied memory needs. You can’t predict in advance what details will be relevant. Hermes handles this better.
You want the agent to surface connections it wasn’t explicitly programmed to find. Semantic search can find relevant memories you didn’t know to look for. An agent might surface a conversation about a client’s concerns from three months ago because it’s semantically relevant to a current project decision — something a structured query wouldn’t catch unless you wrote that query explicitly.
You’re iterating quickly. Hermes has lower upfront design overhead. You don’t need to define a schema before you start storing memories. This makes it faster to build and iterate on.
Memory content is unstructured. If you’re storing conversation summaries, notes, and free-text observations, Hermes handles this more naturally than a rigid relational schema.
Building Persistent Memory in Practice
Regardless of which architecture you choose, several principles apply to any solid persistent memory implementation.
Design Your Memory Write Policy
Decide what gets stored and when. Common strategies:
- Store everything — Simple but noisy. Memory quality degrades as irrelevant records accumulate.
- Summarize and store — After each session, run a summarization step before writing to memory. This stores distilled insight rather than raw transcripts.
- Selective storage — Use a secondary model or rule set to identify memory-worthy content. Only store items above a relevance or importance threshold.
Everyone else built a construction worker.
We built the contractor.
One file at a time.
UI, API, database, deploy.
The summarize-and-store approach tends to work best for most agent use cases. Raw transcripts are expensive to store, embed, and retrieve.
Handle Memory Conflicts
Both architectures need a strategy for conflicting information. What happens when a user’s stored preference contradicts something they just said?
A practical approach: tag memories with a confidence or recency score, and when conflicts are detected during injection, surface both pieces of information to the agent with a note that they may conflict. Let the LLM resolve the ambiguity in context.
Control Context Window Pressure
Injecting too much memory into the prompt is a common mistake. More isn’t always better. Excessive memory injection adds noise, increases cost, and can degrade performance by burying relevant content in irrelevant detail.
A useful heuristic: aim for 10–15% of your context window for injected memory. Leave the rest for the current conversation and task instructions.
Test Memory Recall Quality
Build evaluation into your memory system from day one. Periodically test whether the agent is surfacing the right memories for known scenarios. For Hermes, this means evaluating retrieval quality — are the top-N results actually relevant? For Memarch, it means verifying that your queries return complete, accurate results.
Plan for Memory Hygiene
Both architectures need maintenance. Stale memories — outdated preferences, resolved tasks, superseded facts — reduce memory quality over time. Build in:
- TTL (time-to-live) policies for time-sensitive memories
- Explicit deletion when facts are superseded
- Periodic consolidation that merges related memories into summaries
How MindStudio Fits Into Your Memory Architecture
Building a custom memory system from scratch — whether Memarch or Hermes — requires connecting multiple infrastructure pieces: a database, an embedding pipeline, a retrieval layer, a prompt injection step, and an orchestration layer to tie it all together. That’s significant plumbing before you’ve written a single line of agent logic.
MindStudio handles much of this infrastructure in its no-code agent builder. When building multi-agent workflows in MindStudio, you can connect agents to external data sources — Airtable, Notion, Google Sheets, Pinecone, and 1,000+ other integrations — store and retrieve structured or unstructured data across sessions, and inject that context into your agent’s system prompt, all without writing the retrieval and injection logic yourself.
For teams building on top of Claude or other models who want to extend memory capabilities further, MindStudio’s Agent Skills Plugin (@mindstudio-ai/agent) lets external agents — including Claude Code, LangChain agents, or custom systems — call MindStudio workflows as typed method calls. This means you can build a Memarch-style retrieval workflow or a Hermes-style vector search workflow in MindStudio and expose it as a clean agent.runWorkflow() call that any downstream agent can use. The plugin handles auth, retries, and rate limiting, so the calling agent just gets back structured memory context.
The average agent build on MindStudio takes 15 minutes to an hour. You can try it free at mindstudio.ai.
Frequently Asked Questions
What is a persistent memory system for AI agents?
A persistent memory system allows an AI agent to store and retrieve information across multiple sessions — so it doesn’t start from scratch every time. Without one, agents have no memory of past conversations, user preferences, or previous decisions. Persistent memory typically involves external storage (a database or vector store), a write layer that stores relevant information after each interaction, and a read/injection layer that retrieves and adds stored context to the agent’s prompt before each new interaction.
What’s the difference between Memarch and Hermes memory architectures?
Memarch is a schema-driven, structured memory architecture that organizes information into predefined tiers and retrieves it through explicit queries. Hermes is a retrieval-first architecture that stores memories as embeddings in a vector database and retrieves the most semantically relevant ones at query time. The key tradeoff: Memarch is more predictable and auditable; Hermes is more flexible and contextually intelligent.
Which memory architecture is better for multi-agent systems?
It depends on how much coordination your agents need. For multi-agent workflows where agents share structured data — handoffs, task states, shared knowledge bases — Memarch’s structured schemas reduce ambiguity and prevent write conflicts. For more loosely coupled multi-agent systems where each agent maintains its own memory context, Hermes often works better because it handles diverse, unstructured memory more naturally. Many production systems combine both: a Memarch-style shared knowledge base for structured facts, and Hermes-style personal memory for each agent’s conversational context.
How do you inject memory into an AI agent’s prompt?
The two main injection strategies are prepend injection and RAG-style injection. Prepend injection assembles a memory block and adds it to the beginning of the system prompt — this is the typical Memarch approach. RAG (Retrieval-Augmented Generation) injection retrieves relevant memory chunks based on the current query and inserts them into the prompt at runtime — this is the typical Hermes approach. Both strategies should constrain injected memory to roughly 10–15% of the total context window to avoid noise.
What databases work best for AI agent memory?
For Memarch-style structured memory: PostgreSQL or Firestore for relational/document storage, Redis for fast-access procedural snippets. For Hermes-style vector memory: Pinecone, Weaviate, Chroma, or Qdrant are the most common choices. Pinecone’s overview of vector databases is a solid reference for understanding how vector retrieval works in practice. Many production systems combine both — structured storage for defined entity types (user profiles, task records) and vector storage for unstructured conversational memory.
Does using persistent memory increase the cost of running AI agents?
Yes, in several ways. Injecting memory into the prompt increases token count per call. Running embedding models to vectorize memory adds compute cost. Storage at scale adds infrastructure cost. The main mitigation strategies are: summarizing before storing so you’re embedding distilled insights rather than raw transcripts, capping injected memory to a fixed token budget, and using tiered storage — keeping only the most recent or important memories hot in vector search and archiving older ones to cheaper cold storage.
Key Takeaways
- AI agents need persistent memory to maintain continuity across sessions. Without it, every interaction starts from zero.
- Memarch is the better choice for structured domains, multi-agent coordination, and use cases where auditability matters. It applies structure at write time.
- Hermes is the better choice for open-ended agents, conversational use cases, and rapid iteration. It applies structure at read time via semantic retrieval.
- Most production systems benefit from combining both: Memarch for structured entity data (user profiles, task records), Hermes for unstructured conversational memory.
- Design your write policy, control context window pressure, and build in memory hygiene from the start — these are the failure modes that tend to bite teams later.
- MindStudio’s no-code agent builder handles the infrastructure plumbing — database connections, retrieval, injection — so you can focus on agent behavior rather than memory architecture boilerplate. Try it at mindstudio.ai.