What Is Context Rot in AI Coding Agents and How Do Sub-Agents Fix It?
Context rot degrades AI coding agent performance as your conversation grows. Sub-agents isolate research tasks to keep your main context clean and focused.

When Long Coding Sessions Make AI Agents Unreliable
If you’ve spent a few hours with an AI coding agent — asking it to implement features, fix bugs, read documentation, and refactor code — you’ve probably noticed something odd. The agent starts sharp. By hour two, it’s contradicting earlier decisions, ignoring constraints you set at the start, and making mistakes it wouldn’t have made in the first twenty minutes.
This isn’t random. It has a name: context rot. It’s one of the most common reasons AI coding agents fail in sustained, real-world use, and it’s rarely talked about directly. Understanding what causes it, and how sub-agents address it at the architectural level, is the difference between an agent that stays reliable and one that falls apart mid-session.
What Context Rot Actually Is
Context rot is the gradual degradation in AI agent performance that happens as the context window fills over time. Each message, tool call, file read, and response adds more tokens. Eventually, the model is processing so much information that the signal-to-noise ratio drops — and its output quality drops with it.
The mechanics behind it come down to how attention works in transformer-based language models. Every token in the context window competes for the model’s attention. In a short context, relevant tokens dominate. In a long one — hundreds of messages, thousands of lines of code, dozens of failed debug attempts — they get buried.
Seven tools to build an app. Or just Remy.
Editor, preview, AI agents, deploy — all in one tab. Nothing to install.
The result is a model that over-weights recent tokens, contradicts earlier decisions, loses track of instructions it was given at the start, and increasingly hallucinates details it can no longer reliably retrieve.
The “Lost in the Middle” Problem
This isn’t just intuition. Research from Stanford and other institutions has documented that language models consistently underperform at retrieving information from the middle of long contexts. Models tend to give stronger attention to tokens near the beginning and end of the context window — information buried in the middle gets systematically underweighted.
For a coding session, this means: the architectural decisions you agreed on in the first few messages start to fade. The recent noise — failed attempts, error messages, stale file contents — dominates. The model starts responding to the shape of the conversation rather than its actual goals.
Why Bigger Context Windows Don’t Solve It
The obvious response is: just use a model with a bigger context window. GPT-4o supports 128,000 tokens. Claude 3.5 Sonnet handles 200,000. Gemini 1.5 Pro can manage 1 million. Surely that’s enough?
The problem is that larger windows delay context rot, they don’t prevent it. Empirical testing consistently shows that retrieval accuracy drops as context length increases, even when the relevant information is technically present in the window. A 1M-token context window doesn’t mean the model reads every token with equal care.
Beyond the quality issue, there are practical constraints:
- Noise accumulates faster than signal. Most of what fills a long coding session is noise: intermediate debugging output, outdated file versions, failed tool calls, tangential research threads. This competes with your actual instructions and the current state of your project.
- Early instructions get diluted. A critical constraint you gave the agent in message 3 now has to compete with 150 subsequent messages. The model may technically still “have” it — but it’s less likely to act on it consistently.
- Cost and latency scale linearly. A session consuming 200k tokens is slower and significantly more expensive than one kept at 20k. The larger the context, the harder it is to iterate quickly.
Why AI Coding Agents Are Especially Vulnerable
Context rot affects any AI assistant, but coding agents are particularly exposed. Their work generates a lot of context debris.
Tool Call Accumulation
Coding agents call tools constantly: reading files, running shell commands, searching documentation, executing test suites. Each tool call — and its often-verbose output — gets appended to the context. A single feature implementation might involve 40 or 50 tool calls. The raw output from a test run alone can be thousands of tokens. After a few hours, the tool call history dominates the context.
Multi-File Codebases
When an agent reads a source file, it typically inlines the full content into the context. In any non-trivial project, this adds up quickly. And because code changes as the session progresses, the agent may read the same file multiple times — creating multiple versions in the context, some outdated, some contradictory.
Stale State
- ✕a coding agent
- ✕no-code
- ✕vibe coding
- ✕a faster Cursor
The one that tells the coding agents what to build.
This is one of the most damaging effects. After 50 exchanges, the version of a file sitting in the agent’s context may no longer match what’s actually on disk. The agent is reasoning about a world that no longer exists. The edits it proposes will be based on a stale model of your codebase — leading to wrong assumptions and cascading errors.
Debug Loop Residue
Debugging generates a lot of output that has a short half-life: stack traces, test failures, intermediate variable states. These are useful for about thirty seconds, then immediately become noise. But they persist in the context, and a model affected by context rot will start incorporating old error output into its reasoning as if it were still current.
What Sub-Agents Are
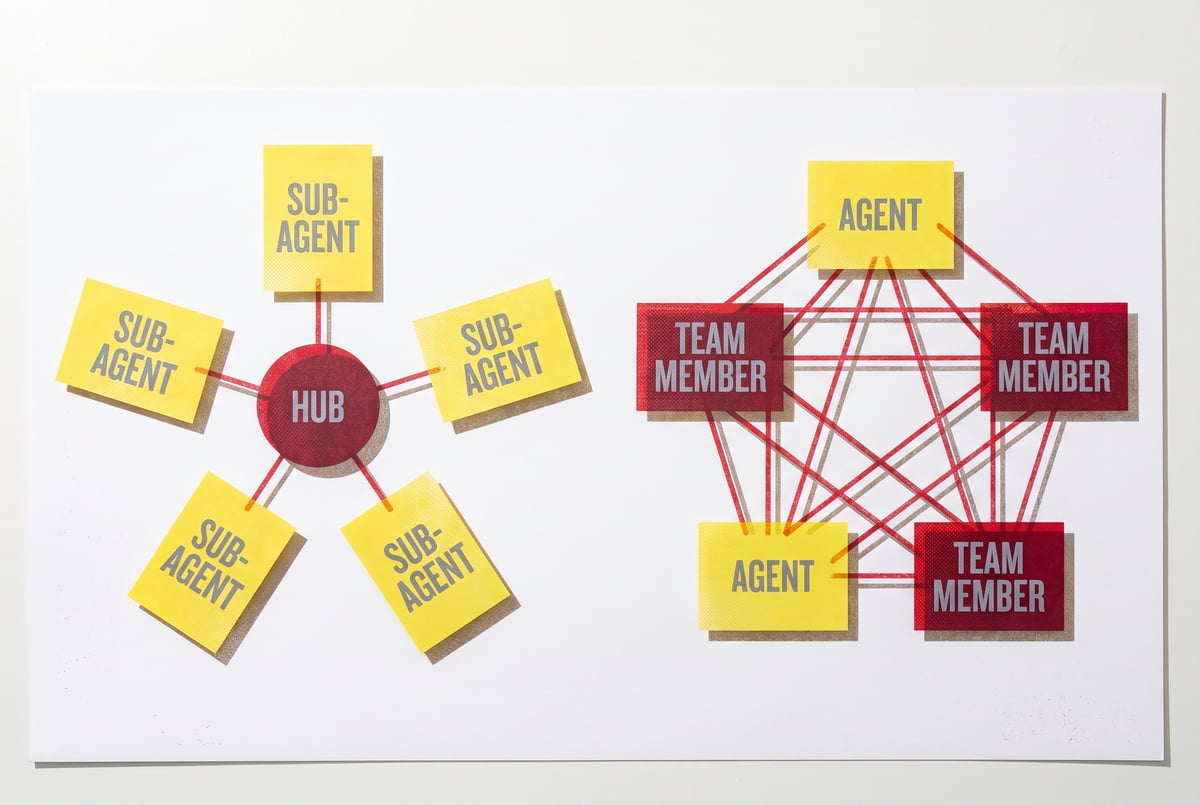
Sub-agents are specialized AI agents that handle discrete, scoped tasks on behalf of a primary orchestrating agent. Instead of one agent trying to do everything in a single growing context, you split the work: the orchestrator manages goals and key decisions, while sub-agents handle specific tasks in their own isolated contexts.
The core mechanism is simple but powerful. When a sub-agent completes its task, only the distilled result comes back to the orchestrator. The sub-agent’s working memory — all the exploration, the intermediate steps, the failed attempts — is discarded. The orchestrator’s context only ever sees the clean output.
Orchestrators vs. Sub-Agents
The orchestrator holds the big picture: the overall goal, the current project state, key decisions already made. It’s the agent that maintains continuity across the full session and coordinates everything else.
Sub-agents are task-specific. An orchestrator building a web application might spin up sub-agents to:
- Research how a third-party API works and return a structured summary
- Search the codebase for relevant existing functions
- Look up security best practices for a specific operation
- Generate and test a specific module in isolation
Each sub-agent starts with a fresh, focused context. When it’s done, it returns a clean answer — not its entire context.
For a deeper look at how AI agent orchestration works at the structural level, the concept maps cleanly onto the task delegation patterns described here.
How Sub-Agents Fix Context Rot
Sub-agents address context rot directly by preventing the primary context from accumulating noise in the first place. Here’s how that plays out in practice.
Isolation of Research Tasks
When the orchestrator needs to research something — how an API behaves, what the best library is for a task, how a legacy module works — it delegates to a sub-agent. The sub-agent does the deep exploration: reading docs, running small tests, exploring code paths. All of that exploration stays in the sub-agent’s context. The orchestrator only receives the final, structured answer.
This is the key asymmetry: the research messiness never touches the main context.
Distillation Over Duplication
A sub-agent doesn’t dump its full context back to the orchestrator. It produces a structured summary — the API’s accepted parameters, the edge cases to watch for, the recommended approach. The orchestrator receives 200 tokens of clean signal instead of 2,000 tokens of raw exploration.
Parallel Execution Without Context Collision

Multiple sub-agents can run simultaneously. While one sub-agent researches an authentication library, another explores the existing database schema. In a single-agent system, these tasks would be sequential — and each would deposit residue in the shared context. With sub-agents, they run in parallel, independently, and return clean outputs that the orchestrator can act on together.
Compartmentalized Failure
When a sub-agent hits a dead end or goes in the wrong direction, that failure stays contained. The orchestrator learns the sub-agent failed (and perhaps the reason), but the failed reasoning doesn’t pollute the main context. The orchestrator can pivot without carrying forward the weight of a failed exploration thread.
Practical Patterns for Using Sub-Agents in Coding Workflows
Understanding the concept is useful. Knowing when and how to deploy sub-agents is what makes it actionable.
The Research-Then-Act Pattern
Before the orchestrator writes any code, it delegates research tasks:
- Sub-agent 1 surveys the existing codebase for auth-related functions and returns a summary.
- Sub-agent 2 looks up current best practices for JWT refresh token rotation and returns five bullet points.
- Orchestrator receives both summaries, forms a plan, then writes the implementation.
The orchestrator’s context stays clean throughout the research phase.
The Validation Pattern
After writing code, the orchestrator delegates validation rather than running tests inline:
- Sub-agent runs the test suite against a specific module and returns: pass/fail, any failing test names, and a short error summary.
The orchestrator gets a structured report — not thousands of lines of test runner output.
The Parallel Exploration Pattern
When facing an architectural decision with multiple valid options, spin up one sub-agent per option:
- Sub-agent A: prototype approach X and report on feasibility, complexity, and blockers.
- Sub-agent B: prototype approach Y and report on the same criteria.
The orchestrator receives two clean comparisons and makes a decision — without its context being polluted by two full exploration threads running in sequence.
The Specialist Pattern
Build persistent sub-agents with specialized knowledge. A “docs reader” sub-agent pre-prompted to extract structured summaries from API documentation. A “security reviewer” sub-agent pre-prompted with your team’s security standards. A “test writer” sub-agent that knows your testing conventions.
Each specialist handles its domain and returns structured output every time, without any of its domain-specific knowledge or working history accumulating in the orchestrator’s context.
Building This in MindStudio
If you want to build orchestrator + sub-agent workflows without managing agent infrastructure from scratch, MindStudio is worth looking at. Its visual workflow builder lets you define distinct agents — an orchestrator for the overall task and separate sub-agents for scoped functions — and connect them so each runs in its own context.
When a sub-agent completes, it returns structured output the orchestrator can use directly. The sub-agent’s working process never enters the main context. This is exactly the architecture described throughout this article, and you can build it without writing infrastructure code.
MindStudio also connects to real tools — file systems, GitHub, documentation sources, web search — through 1,000+ pre-built integrations. The orchestrator stays focused on reasoning and decisions; sub-agents handle the research and validation tasks that would otherwise cause context rot.
Everyone else built a construction worker.
We built the contractor.
One file at a time.
UI, API, database, deploy.
For developers building with external frameworks like Claude Code, LangChain, or CrewAI, the MindStudio Agent Skills Plugin (@mindstudio-ai/agent) lets those agents call MindStudio-built sub-agents as simple method calls. It handles rate limiting, retries, and auth at the infrastructure level — the primary agent just calls a method and gets a result back.
You can start building for free at mindstudio.ai.
Frequently Asked Questions
What is context rot in AI?
Context rot is the degradation in AI agent performance that occurs as the context window fills with tokens over time. The more a session grows — with messages, tool call outputs, file contents, and debugging noise — the harder it becomes for the model to reliably retrieve and act on earlier information. The “lost in the middle” effect, documented in research on long-context language models, shows that models consistently underweight information in the middle of long contexts, favoring content near the beginning and end.
Does a larger context window prevent context rot?
No. Larger context windows delay context rot, but they don’t eliminate it. Retrieval accuracy in language models drops as context length increases, even when the relevant information is technically present. A 1M-token context window still degrades as it fills — and it costs more and runs slower as it does. The underlying attention limitations remain regardless of window size.
What are sub-agents in AI systems?
Sub-agents are AI agents that handle specific, bounded tasks on behalf of an orchestrating primary agent. They operate in their own isolated context, execute a focused task — research, validation, code generation, documentation lookup — and return a clean, distilled result. Only that result enters the orchestrator’s context. The sub-agent’s working process is discarded after use.
How do sub-agents prevent context rot?
Sub-agents prevent context rot by keeping noisy, exploratory work outside the main context entirely. Research, debugging, and exploration happen in sub-agent contexts that are discarded once the task completes. The orchestrator only receives structured summaries. Over a long session, this keeps the orchestrator’s context focused on goals and decisions rather than accumulating the residue of every intermediate step.
What’s the difference between an orchestrator and a sub-agent?
The orchestrator manages the overall goal, coordinates work across sub-agents, and maintains continuity with the user or calling system. Sub-agents execute specific delegated tasks and return results. The key architectural rule is that sub-agents don’t expand the orchestrator’s context — they replace large blocks of messy exploration with small, structured outputs.
Can sub-agents experience context rot themselves?
Yes, but this is usually acceptable because sub-agents handle short, bounded tasks. A sub-agent researching a single API or exploring a specific module finishes quickly, before context rot becomes significant. If a sub-agent’s task is complex enough to risk its own context rot, the solution is the same: break it down further and have it delegate to its own sub-agents. This recursive delegation is the foundation of deep multi-agent hierarchies used in production multi-agent workflow systems.
Key Takeaways
- Context rot is the degradation in AI agent performance that occurs as context windows fill with noise over time — it’s a predictable consequence of how attention mechanisms work, not a random failure.
- Bigger context windows delay the problem but don’t solve it. The “lost in the middle” effect means performance drops even when relevant information is technically present.
- AI coding agents are especially vulnerable because tool calls, file reads, debug output, and failed exploration all accumulate in a single shared context.
- Sub-agents fix context rot by isolating exploratory and research tasks in separate contexts, then returning only the clean, useful result to the orchestrator.
- The core patterns — research-then-act, validation delegation, parallel exploration, and specialist sub-agents — are practical and composable for real coding workflows.
- Platforms like MindStudio let you build these orchestrator/sub-agent architectures visually, without managing the infrastructure layer yourself.